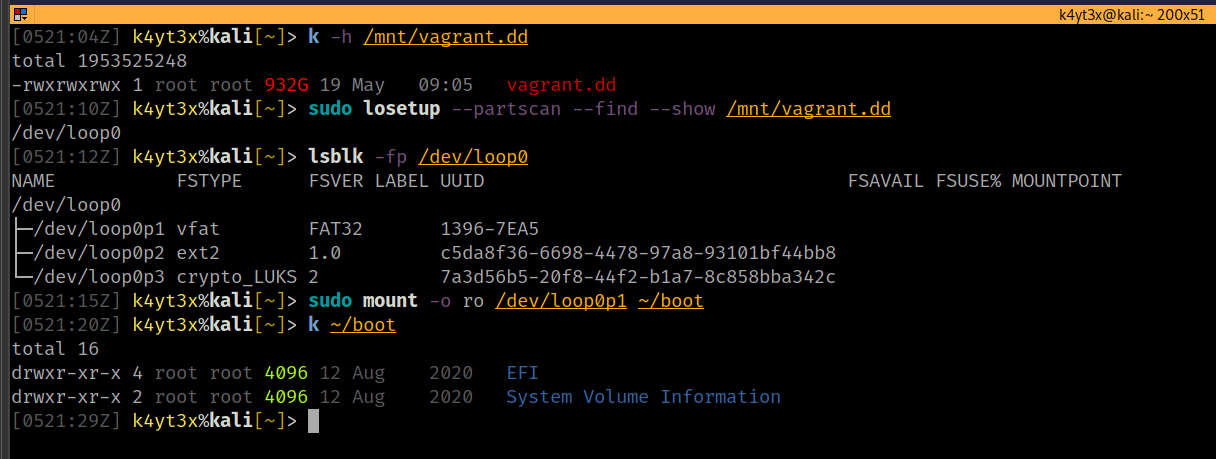
挂载文件系统 在挂载完环回设备后,接下来的挂载就和挂载普通文件系统无异了。只需要用 mount 命令将 loop 设备挂载到任意挂载点即可读取。
1 2 3 4 5
$ sudo mount -o ro /dev/loop0p1 ~/boot $ k ~/boot total 16 drwxr-xr-x 4 root root 4096 12 Aug 2020 EFI drwxr-xr-x 2 root root 4096 12 Aug 2020 System Volume Information
Linux gzip命令介绍 gzip(GNU zip)是一种在Linux系统中常见的命令行压缩工具。它使用DEFLATE压缩算法来减小文件的大小,使文件更易于存储和传输。gzip主要用于压缩文本文件、Tar归档文件和网页。不建议使用gzip来压缩图像、音频、PDF文档和其他已经压缩的二进制文件。
Linux gzip命令适用的Linux版本 gzip命令在大多数Linux发行版中都可以使用,包括Debian、Ubuntu、Alpine、Arch Linux、Kali Linux、RedHat/CentOS、Fedora和Raspbian。如果在某些Linux发行版中无法使用gzip命令,通常可以通过包管理器(如apt、yum或dnf)来安装。
mout Shell代码 sudo losetup -o 32256 /dev/loop1 archlinux-2008.06-core-i686.img sudo mount -o loop /dev/loop1 /mnt/ ls /mnt/ addons archlive.sqfs boot lost+found
事实上,fdisk可以直接查看img文件(虽然功能不全,下面会说到),mount可以自动创建loop设备,所以上面步骤可以简化为: I. 查看信息 Shell代码 sudo fdisk -lu archlinux-2008.06-core-i686.img You must set cylinders. You can do this from the extra functions menu.
Disk archlinux-2008.06-core-i686.img: 0 MB, 0 bytes 53 heads, 12 sectors/track, 0 cylinders, total 0 sectors Units = sectors of 1 * 512 = 512 bytes Disk identifier: 0x00000000
Device Boot Start End Blocks Id System
archlinux-2008.06-core-i686.img1 * 63 629822 314880 83 Linux Partition 1 has different physical/logical beginnings (non-Linux?): phys=(0, 1, 1) logical=(0, 5, 4) Partition 1 has different physical/logical endings: phys=(39, 52, 12) logical=(990, 15, 3)
在执行 Linux 命令时,我们可以把输出重定向到文件中,比如 ls > a.txt,这时我们就不能看到输出了,如果我们既想把输出保存到文件中,又想在屏幕上看到输出内容,就可以使用 tee 命令了。tee 命令读取标准输入,把这些内容同时输出到标准输出和(多个)文件中(read from standard input and write to standard output and files. Copy standard input to each FILE, and also to standard output. If a FILE is -, copy again to standard output.)。
在 tee 中说道:tee 命令可以重定向标准输出到多个文件(tee': Redirect output to multiple files. The tee’ command copies standard input to standard output and also to any files given as arguments. This is useful when you want not only to send some data down a pipe, but also to save a copy.)。要注意的是:在使用管道时,前一个命令的标准错误输出不会被 tee 读取。
实例
格式:
tee file
输出到标准输出的同时,保存到文件 file 中。如果文件不存在,则创建;如果已经存在,则覆盖之。当使用 -a 参数时不会覆盖,而是附加。
输出到标准输出两次。(A FILE of -' causes tee’ to send another copy of input to standard output, but this is typically not that useful as the copies are interleaved.)
格式:
tee file1 file2 -
输出到标准输出两次,同时保存到 file1 和 file2 中。
使用 tee 命令重复输出字符串
echo 12345 | tee
12345
echo 12345 | tee -
12345
12345
echo 12345 | tee - -
12345
12345
12345
使用 tee 命令把标准错误输出也保存到文件,默认情况下 tee 是不会将标准错误内容也保存到文件的,这个时候需要使用 2>$1